Difference between revisions of "Knowledgebase Metrics"
Adminofwiki (Talk | contribs) (→Average Population) |
Adminofwiki (Talk | contribs) (→Cohesion) |
||
| Line 24: | Line 24: | ||
In a semantic association discovery, relationships between instances are traced to discover how two instances are related. If the instances have disconnections among themselves, this may hinder such a search. This metric can be used to indicate the existence of such cases where the knowledgebase has more than one connected component (one being the ideal situation where all instances are connected to each other), indicating areas that need more instances in order to enable instances from one connect component to connect to instances in other connected components. | In a semantic association discovery, relationships between instances are traced to discover how two instances are related. If the instances have disconnections among themselves, this may hinder such a search. This metric can be used to indicate the existence of such cases where the knowledgebase has more than one connected component (one being the ideal situation where all instances are connected to each other), indicating areas that need more instances in order to enable instances from one connect component to connect to instances in other connected components. | ||
| − | The '''cohesion | + | The '''cohesion''' of a knowledgebase is defined as the '''number of connected components''' of the graph representing the knowledgebase. |
==Sources== | ==Sources== | ||
Revision as of 19:47, 23 June 2016
The way data is placed within an ontology is also a very important measure of ontology quality because it can indicate the effectiveness of the ontology design and the amount of real-world knowledge represented by the ontology. Instance metrics include metrics that describe the knowledgebase as a whole, and metrics that describe the way each schema class is being utilized in the knowledgebase.
Average Population
(The average distribution of instances across all classes)
This measure is an indication of the number of instances compared to the number of classes. It can be useful if the ontology developer is not sure if enough instances were extracted compared to the number of classes.
Formally, the average population (AP) of classes in a knowledgebase is defined as the number of instances of the knowledgebase (I) divided by the number of classes defined in the ontology schema (C).
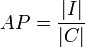
The result will be a real number that shows how well is the data extraction process that was performed to populate the knowledgebase. For example, if the average number of instances per class is low, when read in conjunction with the previous metric, this number would indicate that the instances extracted into the knowledgebase might be insufficient to represent all of the knowledge in the schema. Keep in mind that some of the schema classes might have a very low number or a very high number by the nature of what it is representing.
Class Richness
This metric is related to how instances are distributed across classes. The number of classes that have instances in the knowledgebase is compared with the total number of classes, giving a general idea of how well the knowledgebase utilizes the knowledge modeled by the schema classes. Thus, if the knowledgebase has a very low Class Richness, then the knowledgebase does not have data that exemplifies all the class knowledge that exists in the schema. On the other hand, a knowledgebase that has a very high class richness would indicate that the data in the knowledgebase represents most of the knowledge in the schema.
The class richness (CR) of a knowledgebase is defined as the percentage of the number of non-empty classes (classes with instances) (C') divided by the total number of classes (C) defined in the ontology schema.
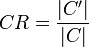
Cohesion
In a semantic association discovery, relationships between instances are traced to discover how two instances are related. If the instances have disconnections among themselves, this may hinder such a search. This metric can be used to indicate the existence of such cases where the knowledgebase has more than one connected component (one being the ideal situation where all instances are connected to each other), indicating areas that need more instances in order to enable instances from one connect component to connect to instances in other connected components.
The cohesion of a knowledgebase is defined as the number of connected components of the graph representing the knowledgebase.
Sources
- Samir Tartir, I. Budak Arpinar, Amit P. Sheth:
Ontological Evaluation and Validation
In: Theory and Applications of Ontology: Computer Applications 2010, pp 115-130
http://link.springer.com/chapter/10.1007%2F978-90-481-8847-5_5
- Samir Tartir, I. Budak Arpinar, Michael Moore, Amit P. Sheth, and Boanerges Aleman-meza:
Ontoqa: Metric-based ontology quality analysis.
In: IEEE Workshop on Knowledge Acquisition from Distributed, Autonomous, Semantically Heterogeneous Data and Knowledge Sources, 2005.
http://cobweb.cs.uga.edu/~budak/papers/ontoqa.pdf